Grande sarebbe il paragone con "Il pensatore" di Rodin. Tuttavia mi piace immagiare me stessa e i miei colleghi come intenti in una profonda meditazione tra gli angusti ma affascinanti cunicoli dei tecnicismi informatico-statistici.
Grande sarebbe il paragone con "Il pensatore" di Rodin. Tuttavia mi piace immagiare me stessa e i miei colleghi come intenti in una profonda meditazione tra gli angusti ma affascinanti cunicoli dei tecnicismi informatico-statistici.Appunto come un pensatore, abbiamo iniziato il nostro percorso interrogandoci su temi generali per poi iniziare una riflessione più attenta su argomenti specifici.
Le prime domande che hanno affollato le nostre menti hanno sollecitato un pensiero più libero e forse anche più creativo: quale fosse il ruolo dei moderni software rispetto all'intelligenza umana? Quali le nuove soluzioni adottate dalla Web 2.0 per supporare la maggiore interazione ricercata dagli utenti, veri e propri "sovrani della rete"? Quali i nuovi tipi di socialità che riesconoa sdoganare le antiche barriere spazio-temporali?
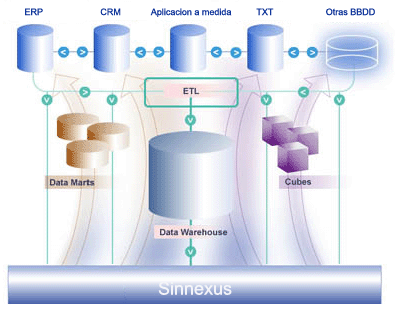
La nostra attenzione si è così spostata sul percorso che conduce alla conoscenza, partendo dagli elementi che ci circondano: dati grezzi in attesa di essere scovati e trasformati in informazioni. Gli strumenti consacrati alla raccolta e alla gestione dei dati sono i DataBase, dei quali abbiamo studiato in maniera approfondita tipologie e strutture. Particolare attenzione è stata dedicata ad uno dei linguaggi più diffusi di interrogazione dei DB: SQL.
Poi ci siamo inoltrati nei sentieri della Business Intellgence. Abbiamo approfondito il discorso sui DBMS, avanzatissimi software per la gestione delle basi di dati, e sui report, documenti azendali che costituiscono fondamentali leve strategiche. Siamo così passati allo studio die software di Query reporting che servono per interrogare in maniera diretta e mirata i dabase, attraverso l'utilizzo del già citato linguaggio SQL.
Il mio percorso è stato in realtà parrallelo a quello svolto dai miei colleghi.
Sull'asse Roma-Madrid sono riuscita a ricostruire il pensiero sviluppato nel corso dell'insegnamento di "Software per la gestione dell'informazione statistica".
Il mio ultimo pensiero si rivolge a Voi: i vostri blog sono stati per me fonte di stimolo.